
この検証では、以下のサービスを使用して、自動化されたサーバーレスデータパイプラインを作成します。
Step Functionsとは
LambdaとStep Functionsの組み合わせ
AWS LambdaとStep Functionsを組み合わせることで、サーバーレスアーキテクチャでの複雑なワークフローの構築が可能になります。
エラーハンドリングやリトライロジックなど組むことで、実行時発生するエラーや問題を効果的に処理することができます。
検証概要
やりたいこと
データファイル(例: CSV形式)がS3バケットにアップロードされるたびに、AWS Lambda関数がトリガーされてデータを処理し、変換後のデータを別のS3バケットに保存します。
また、Amazon EventBridgeを使用して、定期的にデータ処理タスクを実行するスケジュールを設定します。
利用データ
本検証では気象庁の最新気象データをサンプルとして使用します。
気象庁オープンデータ:
https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre1h00_rct.csv
手順
環境構築
S3 データファイル格納フォルダ作成
検証用のバケットを作成し、元データを格納するフォルダと変換後のデータファイルを格納するフォルダをそれぞれ作成します。
・元フォルダ:raw-data/
・変換後フォルダ:processed-data/
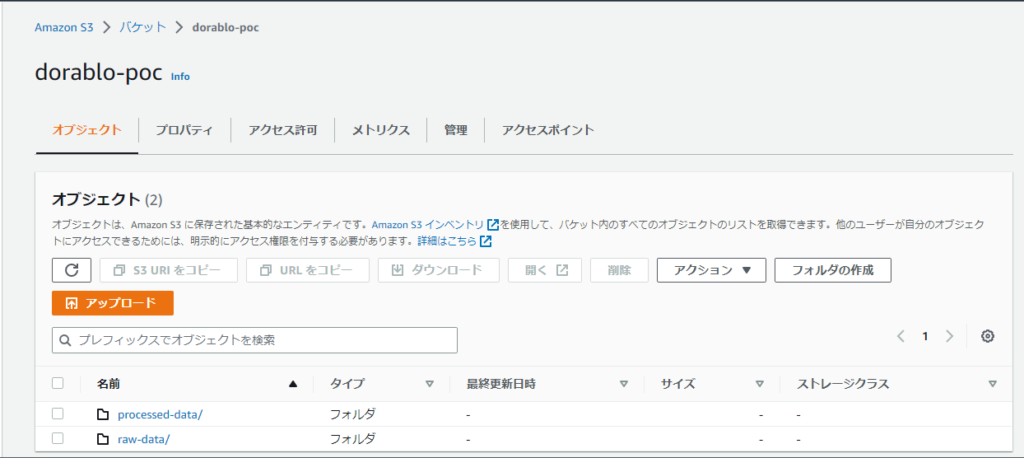
それっぽい名前であれば何でもいいです。
Lambda関数の作成
AWS Lambdaコンソールで新しい関数を作成します。
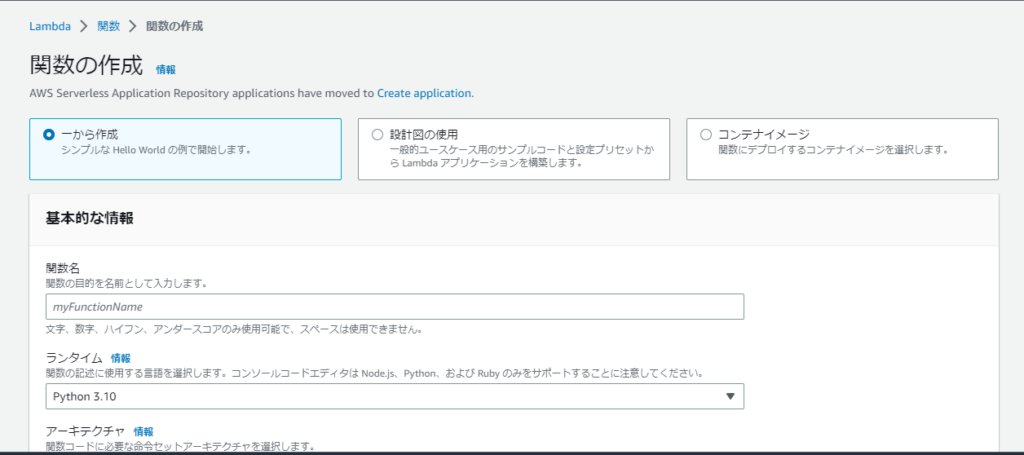
関数名と利用するプログラム言語を設定します。
今回はPythonを選択します。
関数を作成したら、コードタブのfunctionコードを修正します。
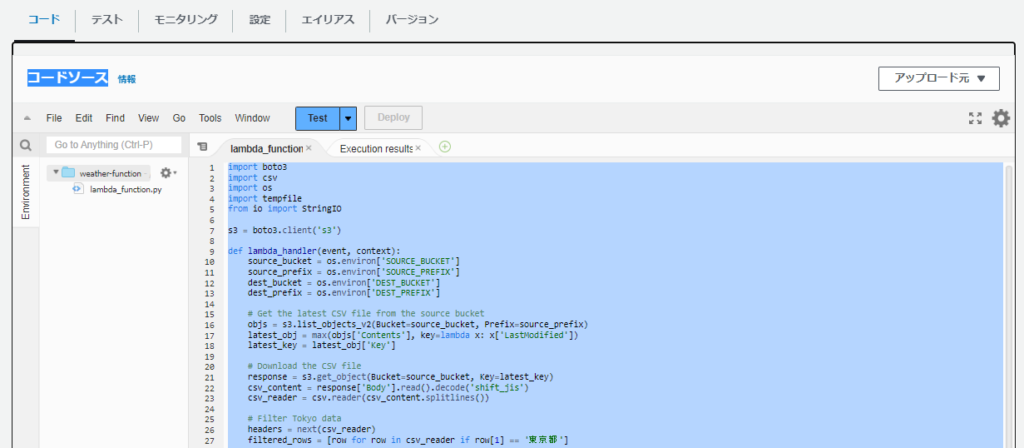
今回利用したコードを転記してますのでご参考に
インフラ屋さんなのでイケてるかどうかは保証しかねます。。。
import boto3
import csv
import os
import tempfile
from io import StringIO
s3 = boto3.client('s3')
def lambda_handler(event, context):
source_bucket = os.environ['SOURCE_BUCKET']
source_prefix = os.environ['SOURCE_PREFIX']
dest_bucket = os.environ['DEST_BUCKET']
dest_prefix = os.environ['DEST_PREFIX']
# Get the latest CSV file from the source bucket
objs = s3.list_objects_v2(Bucket=source_bucket, Prefix=source_prefix)
latest_obj = max(objs['Contents'], key=lambda x: x['LastModified'])
latest_key = latest_obj['Key']
# Download the CSV file
response = s3.get_object(Bucket=source_bucket, Key=latest_key)
csv_content = response['Body'].read().decode('shift_jis')
csv_reader = csv.reader(csv_content.splitlines())
# Filter Tokyo data
headers = next(csv_reader)
filtered_rows = [row for row in csv_reader if row[1] == '東京都']
# Write filtered data to a new CSV file
output = StringIO()
csv_writer = csv.writer(output)
csv_writer.writerow(headers)
csv_writer.writerows(filtered_rows)
# Save the new CSV file to the destination bucket
dest_key = dest_prefix + '/filtered_data.csv'
s3.put_object(Body=output.getvalue(), Bucket=dest_bucket, Key=dest_key)
return {
'statusCode': 200,
'body': f'Filtered data saved to {dest_bucket}/{dest_key}'
}
os.environで取ってるLambdaの環境変数を設定します。
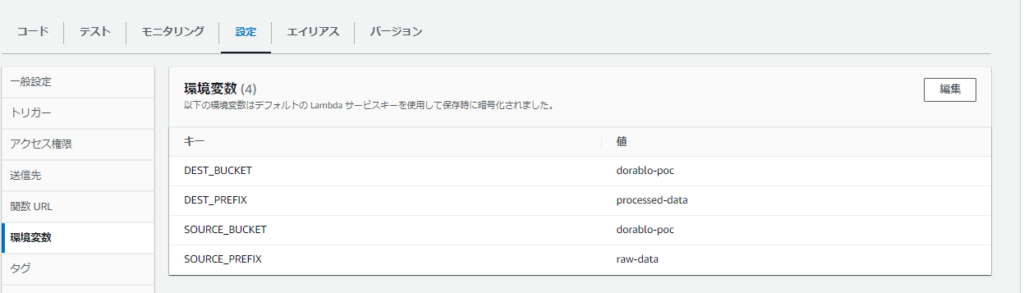
作成できたので、一旦テストしてみましょう!!
[ERROR] ClientError: An error occurred (AccessDenied) when calling the ListObjectsV2 operation: Access Denied
Traceback (most recent call last):
File "/var/task/lambda_function.py", line 16, in lambda_handler
objs = s3.list_objects_v2(Bucket=source_bucket, Prefix=source_prefix)
File "/var/runtime/botocore/client.py", line 530, in _api_call
~~~~~~~~~~~忘れがちですが、Lambda関数に適切なS3アクセス権限を付与する必要があります。忘れがちなのは私だけ???
Lambda関数に権限付与
IAMコンソールを開き「ポリシーの作成」ボタンをクリックします。
JSONタブにポリシーを定義します。
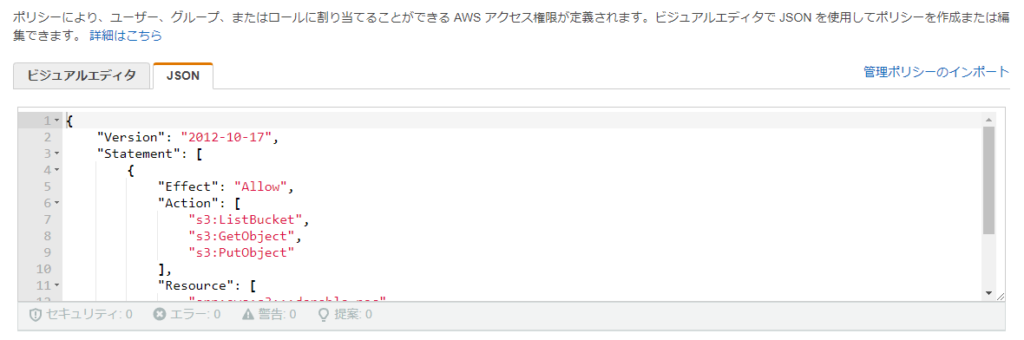
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::dorablo-poc",
"arn:aws:s3:::dorablo-poc/*"
]
}
]
}次に、作成したポリシーをLambda関数の実行ロールにアタッチします。
許可を追加から作成したポリシーを選択し、アタッチします。
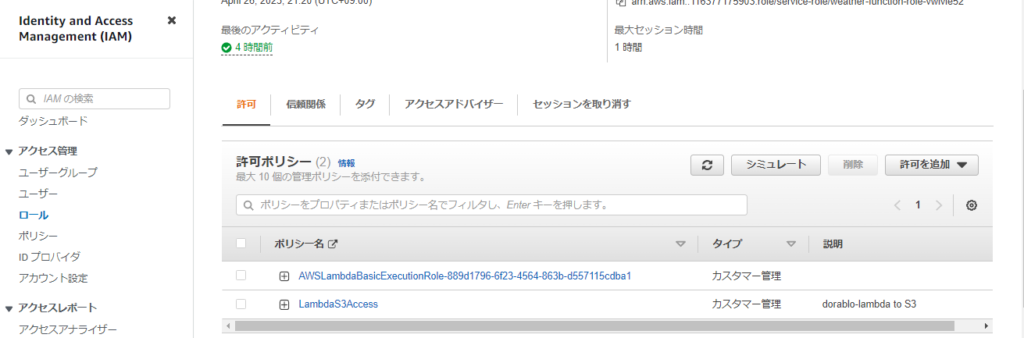
さてもう一度テスト実行してみます。
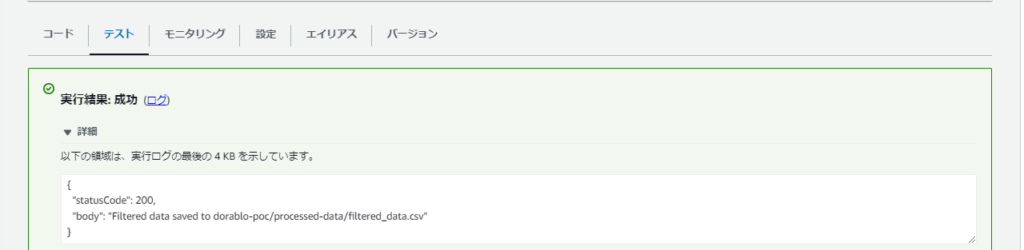
一旦正常で返ってきました!!
本日はここまで、続きは次回の記事にて投稿いたします。






が、今回動作検証となりますので実装しないので各々作りこんでみてください。